Projects
In my research, I focus in inductive biases in machine learning for robotics and control. Within this field I focus on:
- Are inductive biases are beneficial for robot learning algorithms?
- How can inductive biases be incorporated in generic deep learning algorithms?
Within my research, we showed that one can derive robot learning algorithms that cover the complete spectrum between classical engineering and end-to-end deep learning. The inductive biases improve the performance compared to black-box deep learning. We showed that one can also derive inductive biases for deep networks to improve the learned dynamics models and policies. Below, I introduce a few research projects in more detail.
A full list of all publications can be found at Google Scholar
Deep Lagrangian Networks (DeLaN)
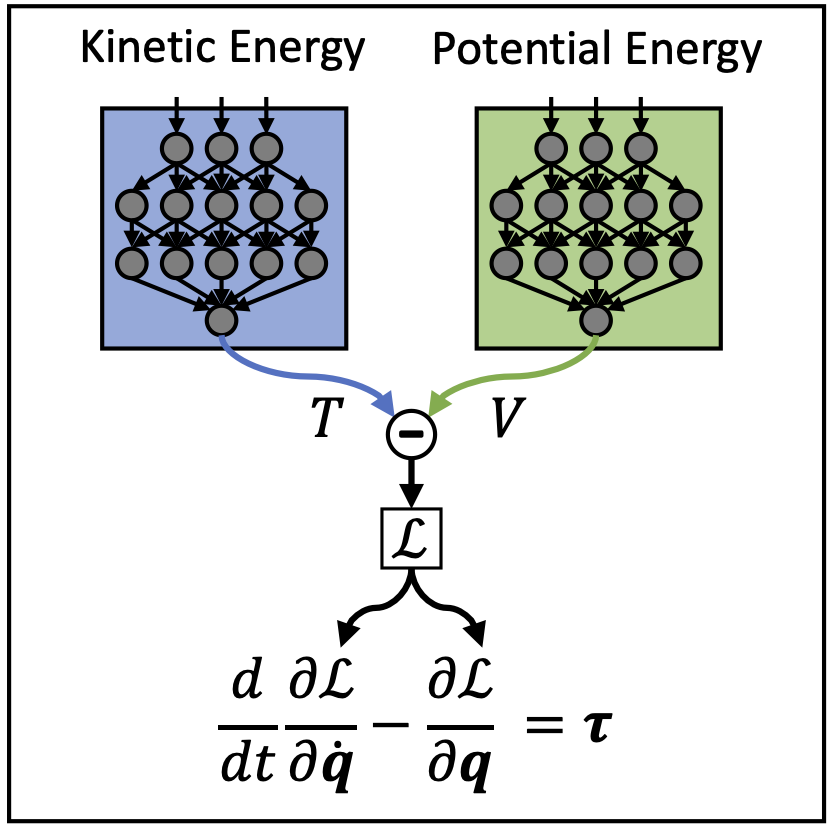
Deep Lagrangian Networks (DeLaN) combines deep networks with Lagrangian mechanics to learn dynamics models that conserve energy. DeLaN uses two deep networks to represent the potential and kinetic energy of the system. These networks are combined to approximate the Lagrangian. The forward and inverse model of the system can be computed using the approximated Lagrangian and the Euler-Lagrange differential equation. DeLaN learns the system energy unsupervised by minimizing the squared residual of the Euler-Lagrange equation. The resulting models retain many advantages of classical system identification techniques but do not require any specific knowledge of the individual system. DeLaN conserves energy, enables energy control, and is interpretable, i.e., can be used to compute Coriolis force, gravitational force, generalized momentum, and other physical quantities. The learned DeLaN models can be used for real-time control of simulated and physical rigid body systems. Compared to standard deep networks, the physics-inspired models learn better models and capture the underlying structure of the dynamics. DeLaN models also enable energy control and successfully swing up the under-actuated Furuta pendulum and the cartpole. Previously, this energy control was not possible using black-box model learning approaches as these cannot learn the energy.
Paper:
-
Lutter, M.; Peters, J. (2021). Combining Physics and Deep Learning to learn Continuous-Time Dynamics Models, Arxiv Preprint Arxiv:2110.01894 [Arxiv] [Code]
-
Lutter, M.; Ritter, C.; Peters, J. (2019). Deep Lagrangian Networks: Using Physics as Model Prior for Deep Learning, International Conference on Learning Representations (ICLR). [Arxiv] [Code]
-
Lutter, M.; Peters, J. (2019). Deep Lagrangian Networks for end-to-end learning of energy-based control for under-actuated systems, International Conference on Intelligent Robots and Systems (IROS). [Arxiv] [Code]
Adversarial Value Iteration in Continuous Time & Space

Robust Fitted Value Iteration (rFVI) learns a robust optimal policy by solving the adversarial reinforcement learning problem with value iteration. Leveraging the non-linear control-affine dynamics of many mechanical systems and the separable state and action reward of many continuous control problems, we derive the optimal policy and optimal adversary in closed form. These analytic expressions enable us to extend value iteration to continuous actions and states as well as solving the two-player zero-sum game. Notably, the resulting algorithms do not require discretization of states or actions. Within the experimental evaluation, we highlighted that these learned policies can control under-actuated systems in real-time and successfully achieve the simulation to reality transfer. When changing the masses of the pendulum, the robust rFVI policy performs better compared to deep reinforcement learning algorithm with uniform domain randomization.
Paper:
-
Lutter, M.; Mannor, S.; Fox, D.; Garg, A.; Peters, J. (2021). Continuous-Time Fitted Value Iteration for Robust Policies, Arxiv Preprint Arxiv:2110.01954 [Arxiv] [Videos] [Code]
-
Lutter, M.; Mannor, S.; Peters, J.; Fox, D.; Garg, A. (2021). Robust Value Iteration for Continuous Control Tasks, Robotics: Science and Systems (RSS) [Arxiv] [Videos] [Code]
-
Lutter, M.; Mannor, S.; Peters, J.; Fox, D.; Garg, A. (2021). Value Iteration in Continuous Actions, States and Time, International Conference on Machine Learning (ICML) [Arxiv] [Videos] [Code]
-
Lutter, M.; Belousov, B.; Listmann, K.; Clever, D.; Peters, J. (2019). HJB Optimal Feedback Control with Deep Differential Value Functions and Action Constraints, Conference on Robot Learning (CoRL) [Arxiv]
Differentiable Newton-Euler-Algorithms

The Differentiable Newton-Euler Algorithm (DiffNEA) can infer physically consistent simulator parameters for rigid body systems augmented with various friction models as well as systems with non-holonomic constraints. In contrast to the classical approaches, this approach leverages automatic differentiation, virtual parameters, and gradient-based optimization to infer parameters that are guaranteed to be physically plausible. DiffNEA excels when extrapolation is required as the identified parameters are globally valid. DiffNEA is able to learn an accurate dynamics model of ball in a cup that includes the string and cup dynamics with only 4 minutes of data. When used for model-based RL, a policy is obtained that transfers to the physical system. The black box deep networks were not able to solve the task. The reinforcement learning easily exploits the black box dynamics models and converges to random movements. Therefore, the DiffNEA model enables generalization beyond the training domain and is very data efficient due to the incorporated structure.
Paper:
-
Lutter, M.*; Silberbauer, J.*; Watson, J.; Peters, J. (2020). Differentiable Physics Models for Real-world Offline Model-based Reinforcement Learning, International Conference on Robotics and Automation (ICRA) [Arxiv] [Videos]
-
Lutter, M.*; Silberbauer, J.*; Watson, J.; Peters, J. (2020). A Differentiable Newton Euler Algorithm for Multi-body Model Learning, ICML Workshop on Inductive Biases, Invariances and Generalization in RL [Arxiv]
Robot Juggling

Paper: